本文根据第23期美团技术沙龙演讲内容整理而成。
背景
美团酒旅有很多条业务线,例如酒店、门票、火车票等等,每种业务都有结算诉求,而结算处于整个交易的最后一环不可缺少,因此我们将结算平台化,来满足业务的结算诉求。结算平台通过业务需求以及我们对业务的理解,沉淀了各种能力并构建了丰富的能力地图。
我们将业务的发展归纳为几个阶段,例如业务孵化阶段,快速抢占市场扩大覆盖阶段,市场稳定后急需盈利阶段,国内业务稳定后的国际化阶段,业务发展的各个阶段都能在结算平台找到相应的能力支持。业务孵化阶段讲究的是低成本试错,我们将结算的核心流程,账单->付款->发票等模块平台化,新业务接入只需要5~10天。我们的预付款结算、分销结算、阶梯返佣结算、地推结算能力能快速的帮业务抢占市场实现盈利。
我们的汇率管理,多币种,多时区结算能力可以助力业务开展海外市场。当前结算平台支持美团酒旅4个事业部、17条业务线,涵盖境内、境外等业务的线上结算,后边我主要介绍下对账平台的实践即账单的实践。
对账平台的重要性
对账是平台化的第一环,它需要算清楚商家和美团的收益明细,后续的付款,发票等,都是基于对账进行开展的。同时它需要对接酒旅的各个订单中心,不同业务的订单具体实现和业务流程不同,不同的业务对账规则和时机也不相同,同时对账每天需要处理数百万条交易明细。
如何解决订单、对账层面的差异?每天处理数百万交易明细,如何高效准确的处理这些数据?17条业务线如何做隔离、定制、个性化扩容?其中面临了很多挑战,这也是为什么要讲对账的原因。
早期的系统实践及优化
早期系统实践
账单的生成逻辑主要分两部分:
- 通过订单中心,供应链分别获取交易数据、商家基本信息、结算规则。
- 基于交易数据、商家信息、结算规则生成对账单。
早期结算系统基于酒店业务实现,有很重的业务特性,模式是期末模式。比如账期是6月1日到6月30日,会在7月1日时执行以上两步操作,结算需要关注业务逻辑。这种模式存在很多问题,比如业务是灵活多变的,结算往往7月1日时才能感知到业务的变化,同时需要处理整个月的交易数据,这样就需要结算有很强的机动能力应对变化,很强的数据处理能力。
早期的系统架构和实现有一些问题,比如采用单线程,Pull的模式去获取数据,生成账单,虽然部署了很多台Server,但其实同一时刻只有一台Server在工作,有严重的资源浪费,同时数据处理效率较低。本应7月1日进行结账,因为业务变更,数据处理效率低,出账往往会拖到7月底,商家体验非常差。当时除了酒店业务之外,门票、火车票业务都处于孵化阶段也有结算需求,比较紧迫的任务有两个,一个是快速的解决酒店结账不及时的问题,另外一个是支持新业务的结算需求。所以当时的策略是,优化老系统让酒店业务平稳运行,搭建新的结算平台支持新业务的孵化。
按时结账优化
优化的策略有两点:
- 和上游约定业务变更流程,需要提前告知结算,结算提前做系统升级。
- 结算提高数据处理能力。
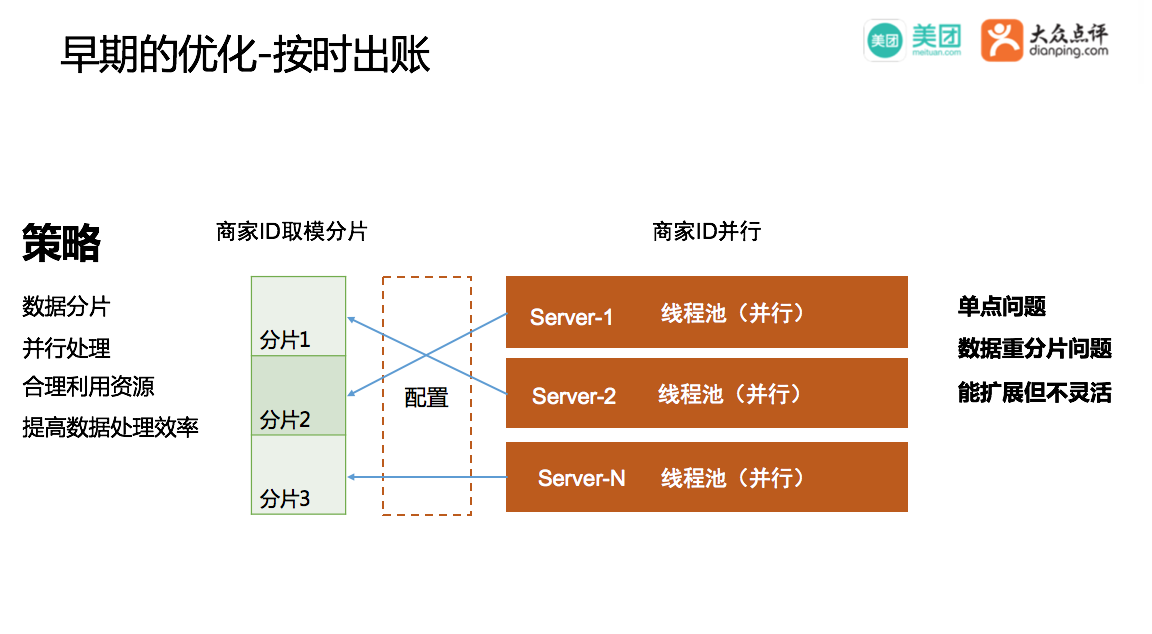
提高数据处理能力思路是:单线程改多线程,串行改并行,单机计算改分布式计算。具体做法是:商家ID维度用取模的方式分片,通过配置将不同的分片配置到不同的Server,同时每个Server上有单独的线程池,可以在商家ID的维度并行获取数据,处理账单。这样虽然能快了起来,但是它又引入了一些新的问题。
比如单点问题,如果Server2宕机了,配置不具备自动Rebalance的能力,就需要结合报警来人工处理,运维压力会变大。如果继续提升处理能力,就需要更多的数据分片,更多的Server资源,这时需要去重新处理分片和配置的逻辑,虽然它是可扩展的,但是并不灵活。
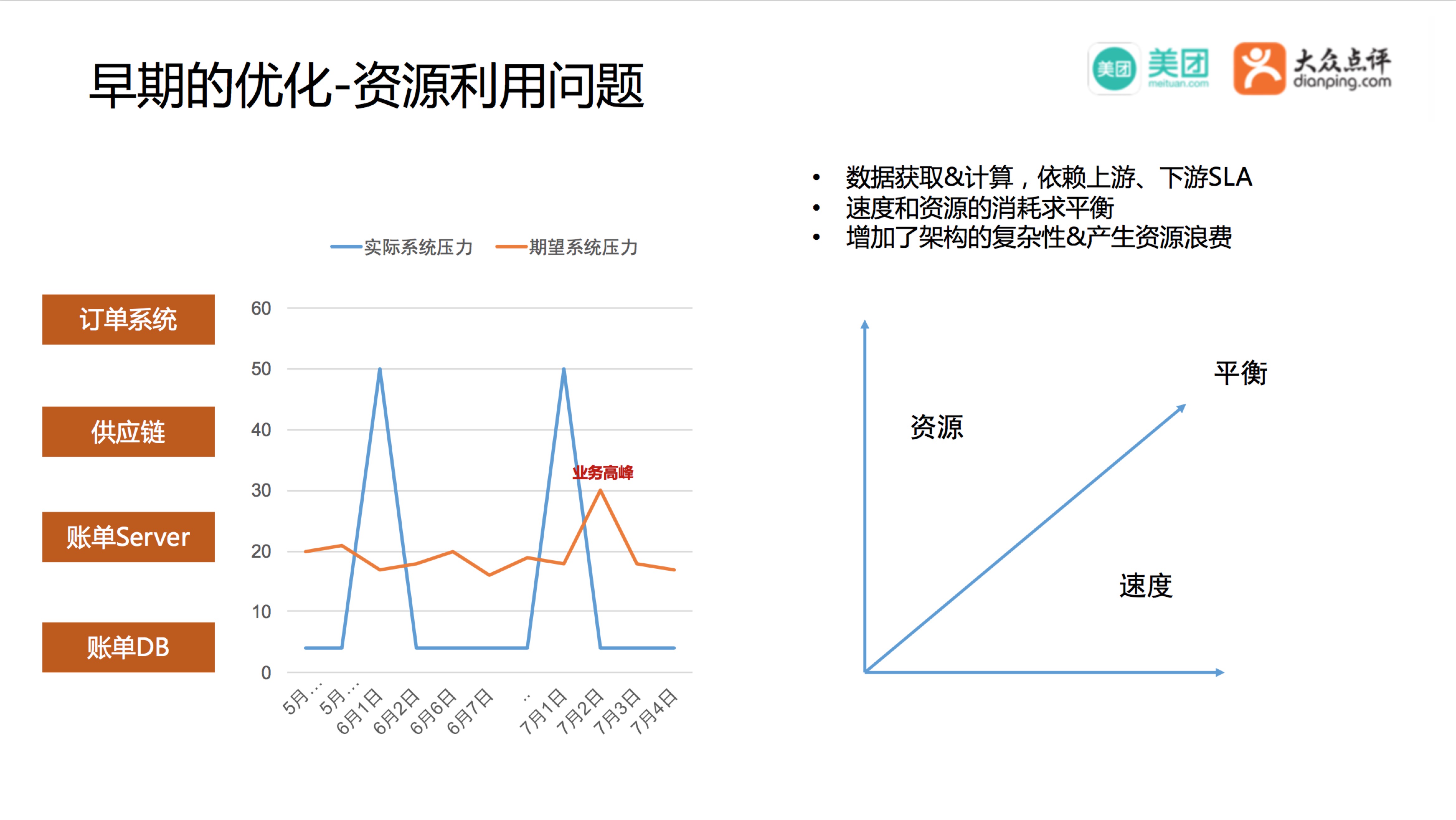
资源利用率波动也比较大,在7月1日处理整个月的数据,资源利用率(蓝线),在月初的时候最高,平时的时候基本上接近于0。比较健康的资源利用率,应该像黄线一样,虽然会有业务的峰值,但是整体上来看是趋于平稳的。如果是蓝线这样的资源利用,就会导致订单系统、结算系统、DB,都需要按照业务的峰值来部署,会产生资源浪费,最后我们在速度和资源的使用上求一个平衡,通过这些优化做到了及时结账。
但还遗留了如下问题:
- 单点问题。
- 提升数据处理效率产生资源浪费。
- 系统处理能力可扩展,但是不够灵活优雅。
- 业务逻辑和结算逻辑严重耦合。
对账平台化及高性能实践
上边这些问题在对账平台化时都需要解决,尤其是逻辑耦合问题,如果不解决,后续对接的业务越多,步伐越沉重,最终会拖慢业务的发展。解决这个问题需要优化结算系统的业务架构,需要抽象一套订单模型,商家模型,计算规则模型,这些模型要足够通用,在兼容各个业务差异同时又要有一定的扩展和定制能力,模型的抽象是平台化的关键。
业务架构优化
订单模型抽象
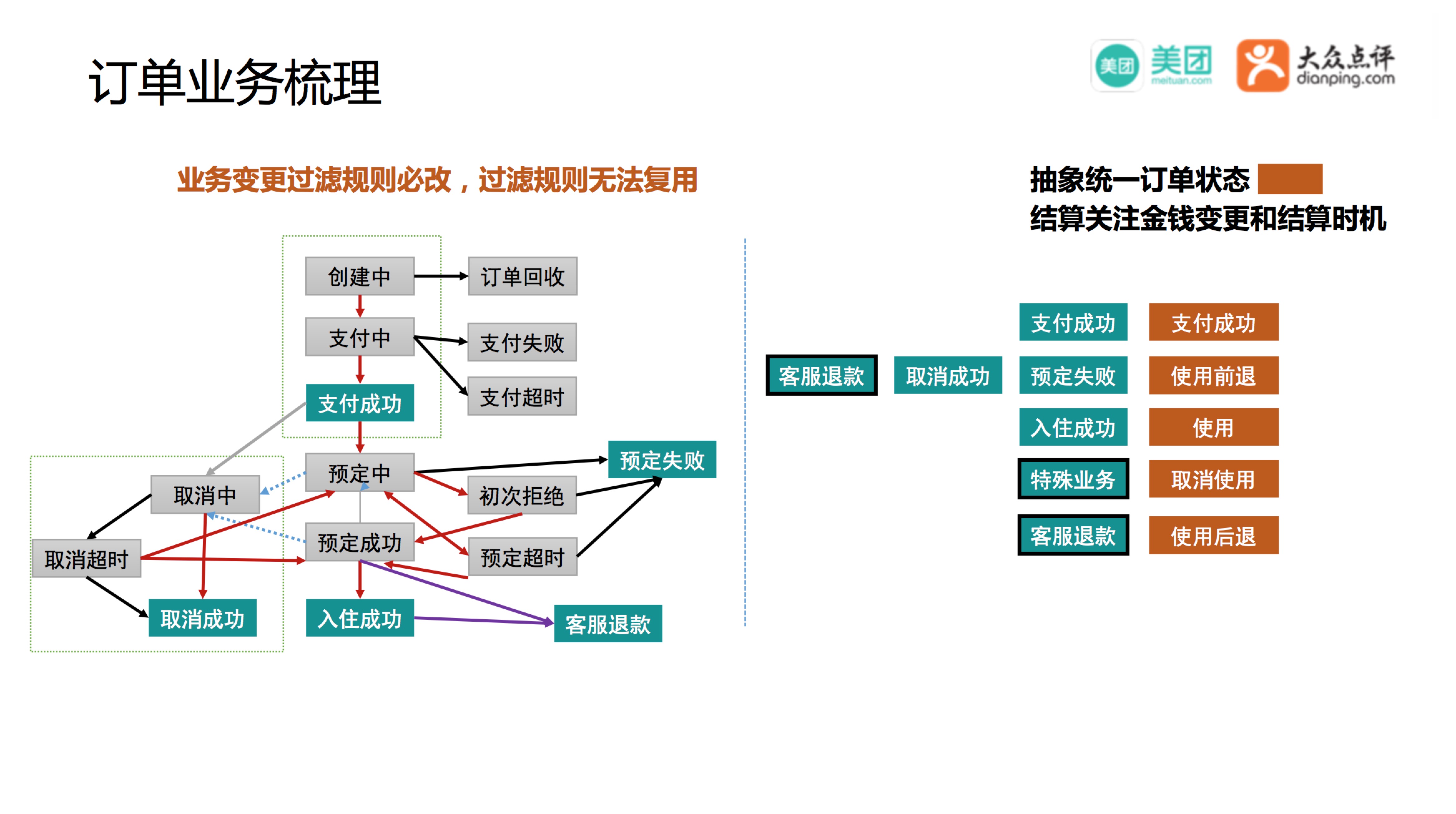
如上图订单状态机所示业务非常复杂,状态变更的轨迹订单如果不记录清楚,事后结算时很难回溯出来当时的交易情况。结算关注金钱变更和结算时机因此需要分析订单的状态机,过滤出结算要关注的状态,在上图中我用蓝色表示,业务变更会导致状态机的设计变更同时会影响过滤逻辑,这个是业务和结算耦合的关键点,不同的业务玩法不一样,状态机也不一样,过滤逻辑完全无法复用。
结算抽象了一组统一的订单状态来描述订单的整个生命周期:支付成功,使用前退、使用、取消使用、使用后退。它们所代表的含义如字面上一样,简单便于理解,每来一条业务线,将订单的原始状态和结算抽象的状态做映射,就能解决订单层面的差异。以酒店为例:预定周日晚上的酒店,周四行程变更无法入住,周五找客服退款,客服退款成功,这个对应使用前退,客服退款在一些特殊的场景也会对应到使用后退,最终解决了订单状态层面的差异。
计算规则抽象
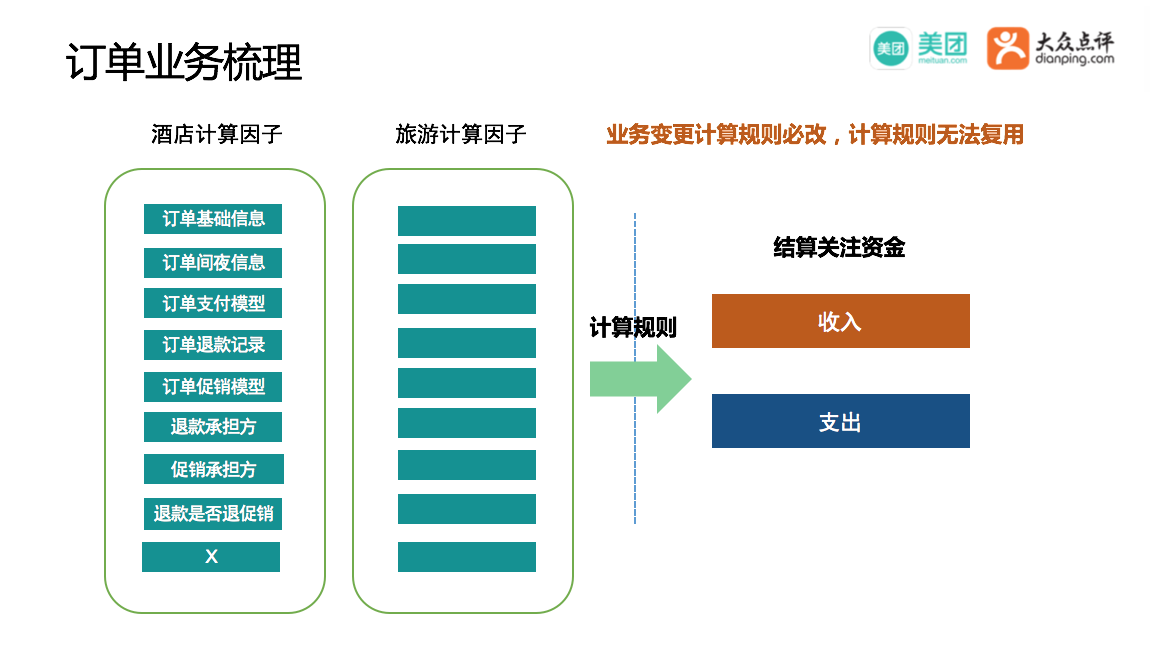
状态过滤出来后要计算这笔交易商家和美团分别的收入和支出是多少。如上图所示酒店要计算收入和支出需要订单的基础信息、间夜信息等因子,这些因子可能散落在各个数据表中,收集和计算非常复杂,业务变更会导致计算因子和计算逻辑变更,不同业务计算因子不相同,所以它很难复用。
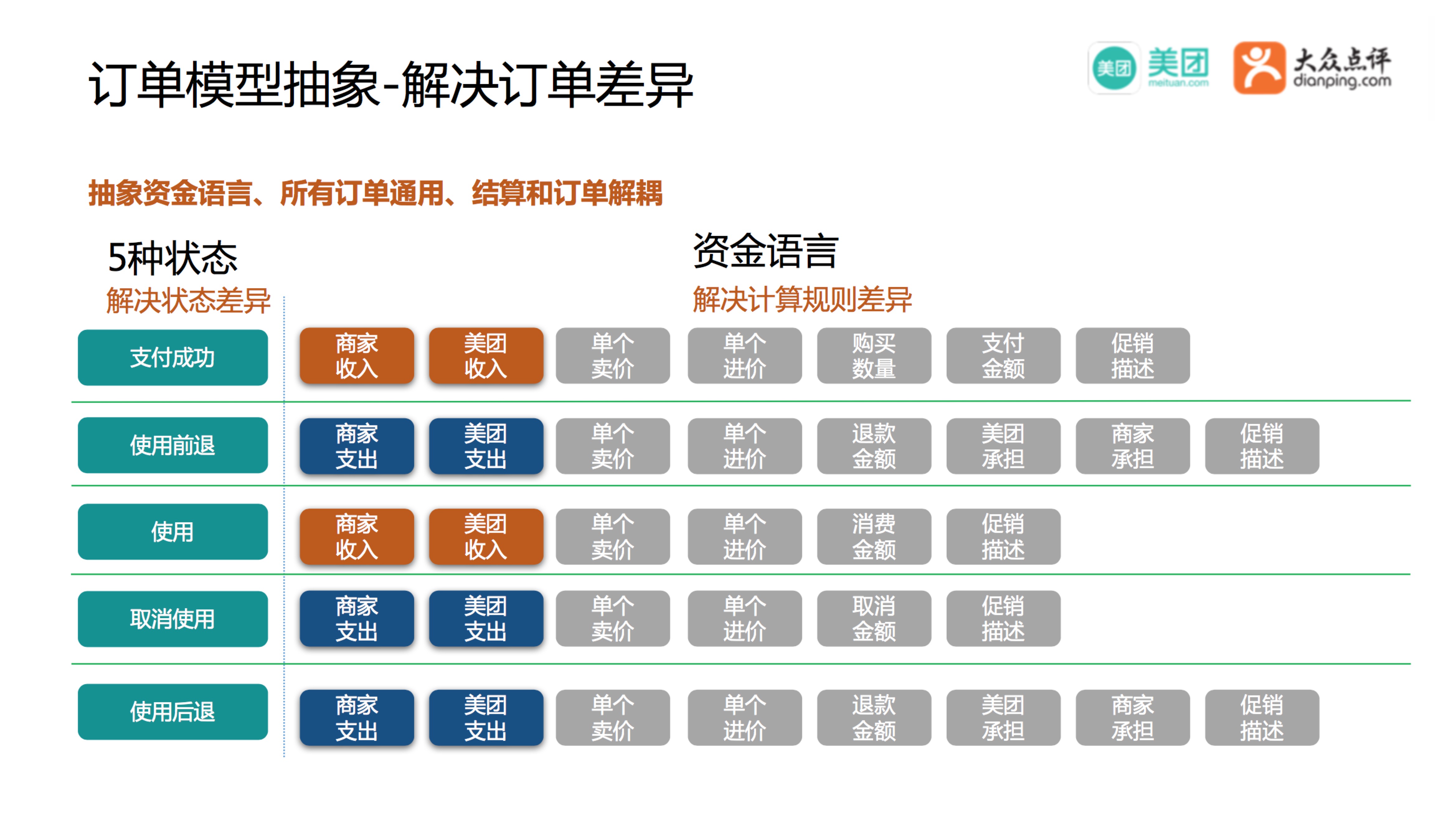
结合前边抽象的订单状态,以及结算关注的收入和支出,我们抽象出来一套资金语言,它由5种状态+资金描述组成,所有订单通用,从而做到结算和订单的彻底解耦。例如“支付成功状态”、“使用状态”对应收入;“使用前退状态”、“取消使用状态”、“使用后退状态”对应支出。资金描述包含具体的收入、支出金额,以及收入、支出的具体描述。商家收入= 单个进价 * 购买数量 - 商家承担促销;美团收入=总卖价 - 总进价 - 美团承担促销,最终商家的收入=总收入-总支出,通过资金语言能推算出收入和支出的具体由来。
资金语言是结算和订单的标准协议,不管什么样的业务,数据结构和业务流程怎么设计,都按照标准协议来,只要协议不变,不管是订单变化还是结算变化都不会相互影响,订单和结算也就具备了独立演进的可能。
商家信息抽象
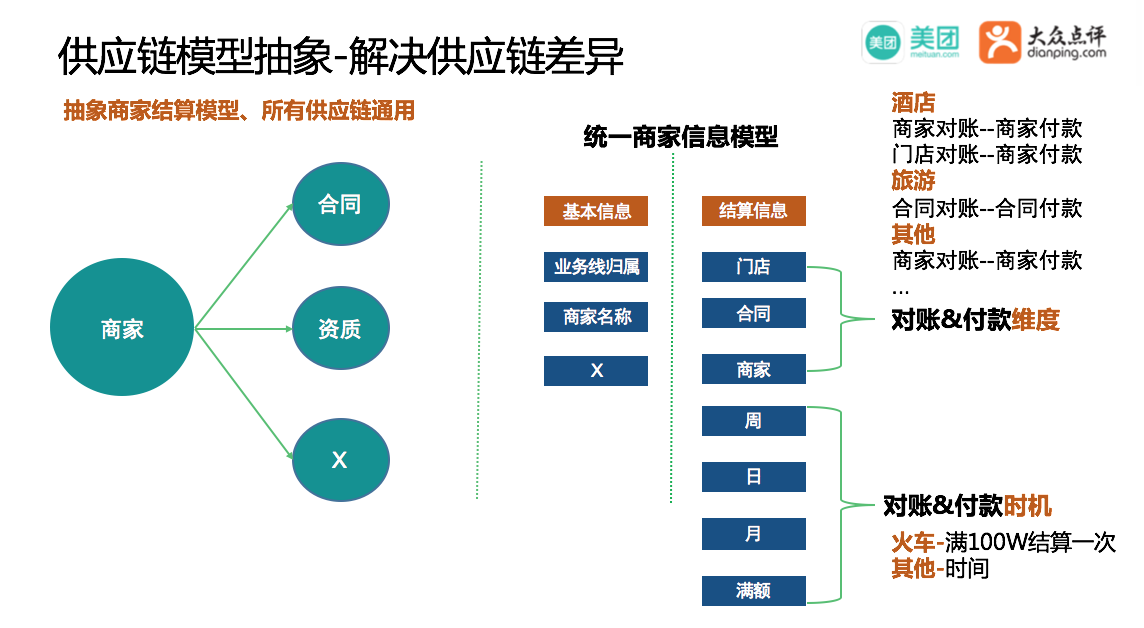
商家关联的信息有很多,例如合同、资质等等,但是结算关注的是这个商家的身份信息,我们将这类信息抽象为商家的基本信息,同时也需要关注商家的对账和付款规则,我们将这类信息抽象为结算信息,结算信息包含对账和付款的维度和时机。对账和付款不同业务维度和时机都不相同,我们将这些信息抽象出来,只要新业务维度和时机在这些规则之内,就能很好的复用,最终解决了供应链层面的差异。
对账平台设计
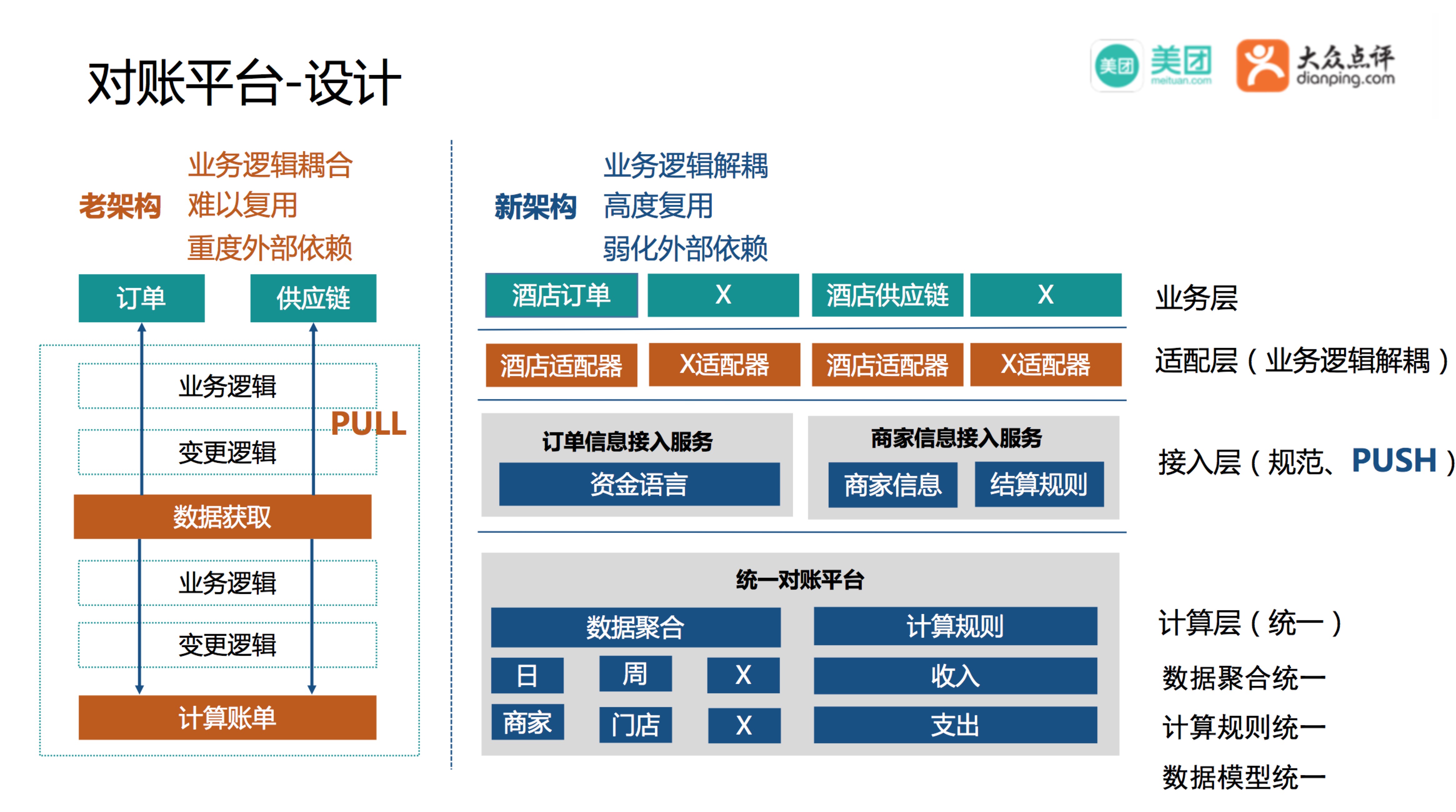
如上图所示。
老架构
数据获取采用PULL模式,如果上游故障会导致无法获取数据,从而影响账单计算,重度外部依赖。不管是数据获取还是计算账单都需要穿透两层业务逻辑,业务逻辑严重耦合难以复用。
新架构
抽象了资金语言,商家信息,结算规则,标准化了接入规范,数据接入采用PUSH的模式,业务产生了交易,新签约了商家只要能将数据按时的PUSH过来就能按时结账,结算被动接收数据,轻度外部依赖。新架构设计了适配层,用来做业务数据和标准协议的适配,适配层逻辑结算和业务都可以做,但是考虑到业务侧的同学更了解业务,业务变更自己修改适配层不需要找结算排期更灵活,我们将适配层交给业务团队来做,每来一个新业务只需要一个小的适配块,就能快速接入。通过抽象的模型和标准协议,对账平台做到了数据聚合统一,计算规则统一,数据模型统一,从而达到了高度复用,结算和业务解耦。历史上酒店和旅游订单发生过多次重构,对结算基本无影响。人员也得到了高度复用,当前对账模块只有4名RD对接了17条业务线。
对账平台具体实践
对账平台实践主要关注如下四点:
- 实时性设计,我们希望订单产生交易商家立刻能看到自己的收入,同时希望解决资源利用率的问题。
- 高性能设计,每天数百万交易明细,每个账期需要处理数百万账单,怎么保证这些数据的生产和计算准确、高效?
- 隔离和定制,结算对接了17条业务线,每个业务体量不同,业务逻辑也会有一定的差异,多个业务之间怎么隔离?怎么做到业务之间相互不影响?
- 可扩展性设计,业务快速规模化以后,系统的处理能力可扩展,满足业务的发展预期。
实时性设计
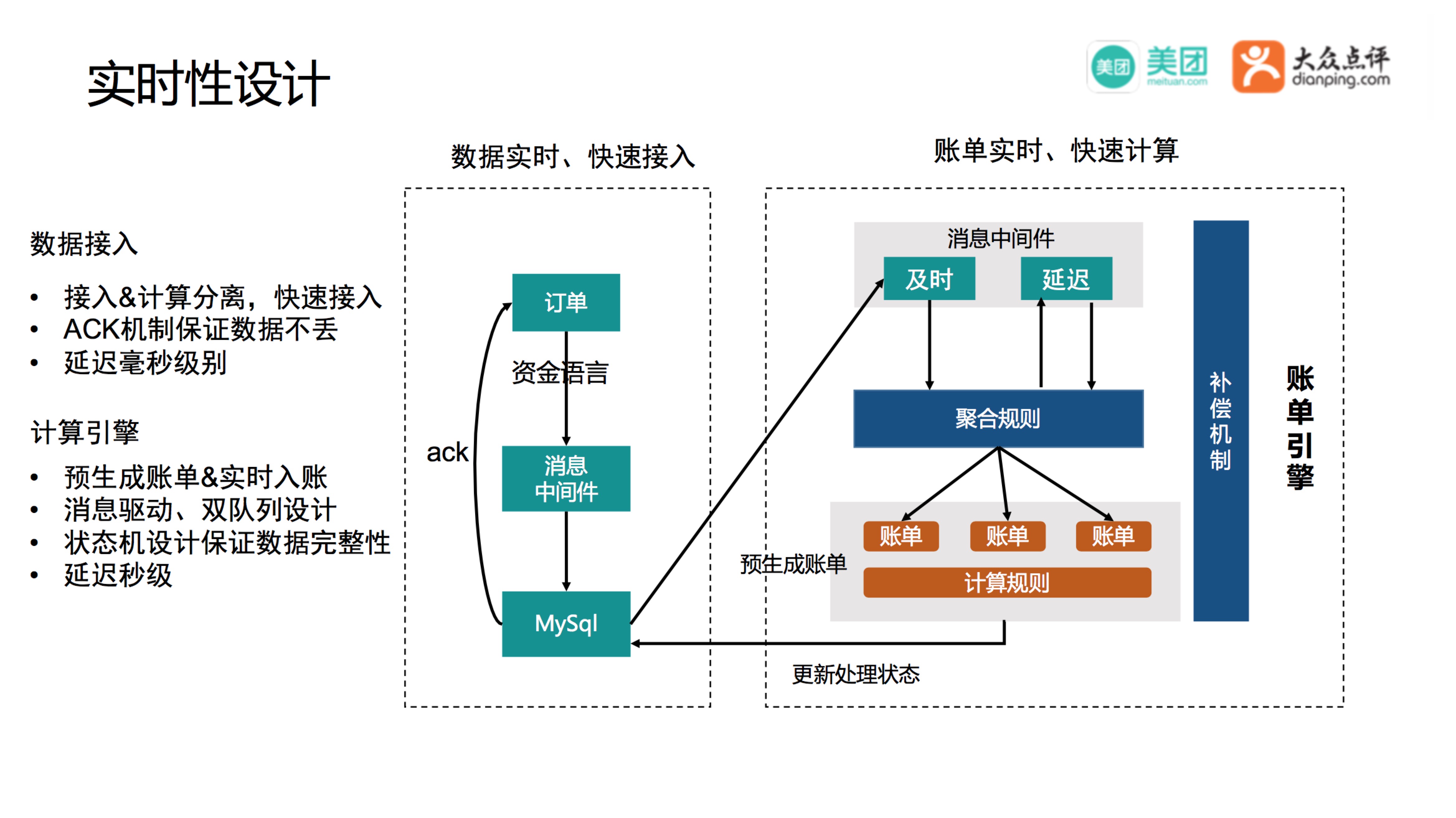
数据接入
订单产生交易,将交易转为资金语言,通过消息中间件(Mafka)实时的推送给结算,结算只做必要的校验,完成后数据落到MySQL中,此时数据的状态是未处理,这一步设计了ACK机制保证数据不丢。落库后会给账单引擎发一个消息,说有一条数据要处理了。数据的接入和账单引擎的计算做了分离,数据的接入非常快,基本延迟在毫秒级别。
账单引擎
账单引擎会在6月1日生成6月1日到6月30日的空账单,数据经过聚合规则,进入到相应的账单,同时触发账单计算规则,完成账单的实时计算。一些特殊的情况例如数据产生在6月1日,结算日期是6月2日,会将这个消息转发到Mafka的延迟队列,在6月2日重新消费这条消息,数据处理成功后,数据的状态变更为已处理。
账单引擎的补偿和监控机制是通过对数据的状态控制来实现的,例如6月1日到30日,商家A一共产生了1万条交易明细,已处理的数据只有8千条,那剩下的2千条要么就是在途,要么就是消息丢了,或者系统Bug,会有一定的监控和补偿策略来保证数据的完整性,账单引擎处理具体的交易明细延迟在秒级。
高性能设计
提高账单的处理效率需要从两个维度出发:
- 每天要处理对账单数量大概在百万级别,一个一个处理是非常慢的,所以要尽可能在对账单维度提高并发度。
- 每个对账单要接收的流水数量也不相同,可能单对账单同一时刻的并发度会很高,所以要尽可能提高单对账单的并行度。
提高高并发设计
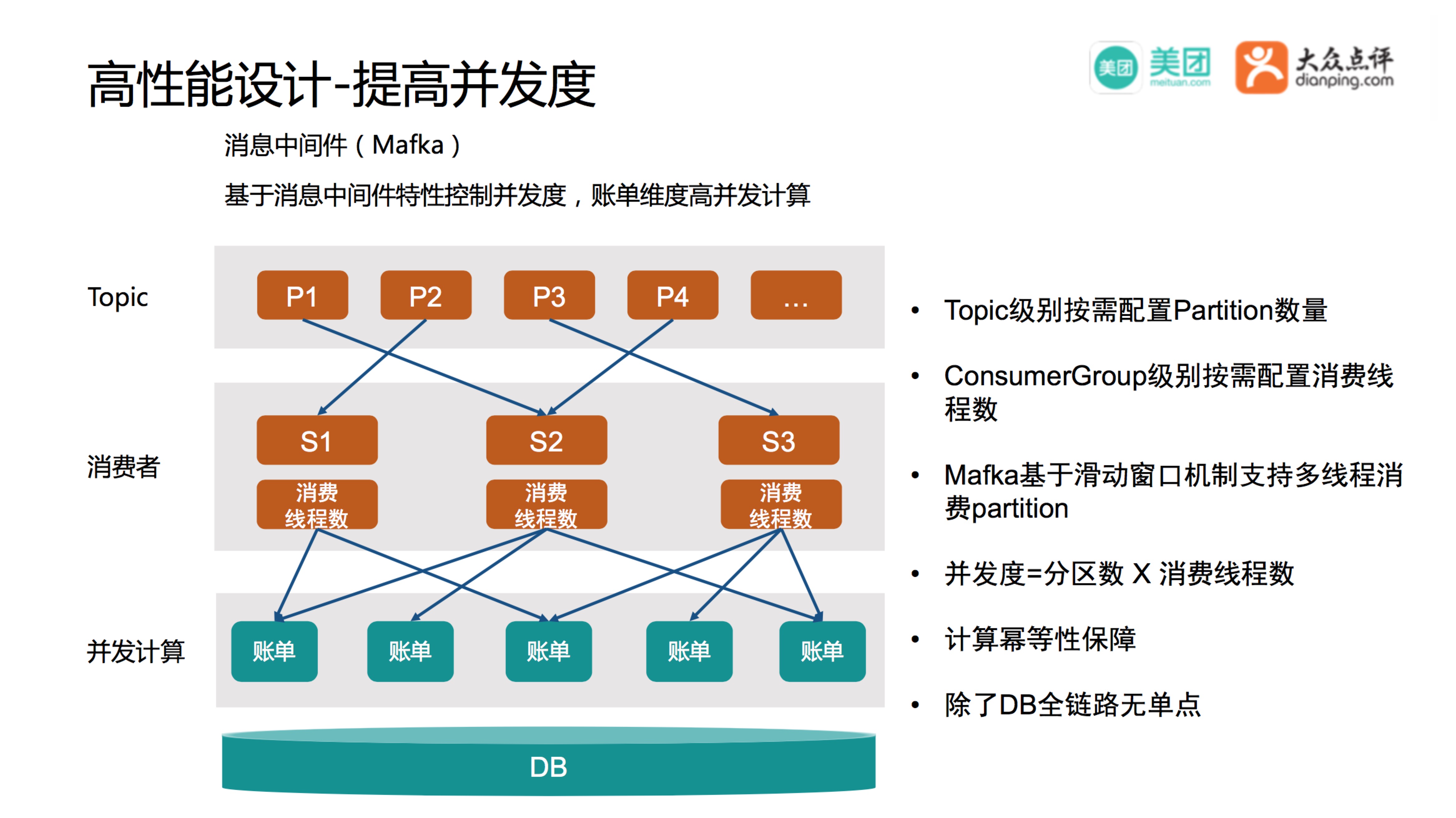
我们通过消息中间件Mafka来提高并发度,在Topic的维度拆分多个Partition,不同的ConsumerGroup配置不同的消费线程数,Mafka基于滑动窗口机制实现了多线程消费同一个Partition的数据,所以可以做到并发度= Partition数量 * 消费线程数,在数据处理上做了幂等性保障,能确保数据的正确处理。从架构上来看除了DB之外全链路无单点,比如某个Server挂了以后,通过Mafka的Rebalance机制,将Partition自动分配给别的Server,消除了Server层面的单点问题。
提高并行度设计
单个对账单包含了多条交易明细,账单的总金额是多条交易明细金额的累加,并发度上来以后,会产生线程安全性问题,怎么保证账单总金额的数据准确性?常规实现:
//事务保证原子性
try {
Lock lock = distributedLockManager
.getReentrantLock(statementId);//账单维度锁
lock.lock(); //获取锁,存在阻塞
insert(detail);//写入明细
compute(statementId);//计算账单
} finally {
lock.unlock();// 释放锁
}
如上边的伪代码所示,要有一个事务保证明细写入和账单金额计算的原子性,其次是获取分布式锁,写入明细,计算账单,因为锁的缘故单账单的并发度是N,并行度是1,并行度低的结果会导致消息出列变慢,单个账单的处理效率变低,有了事务也会有一定的性能开销。怎么提高并行度,怎么减少事务的粒度成为单账单维度高性能计算的关键问题。
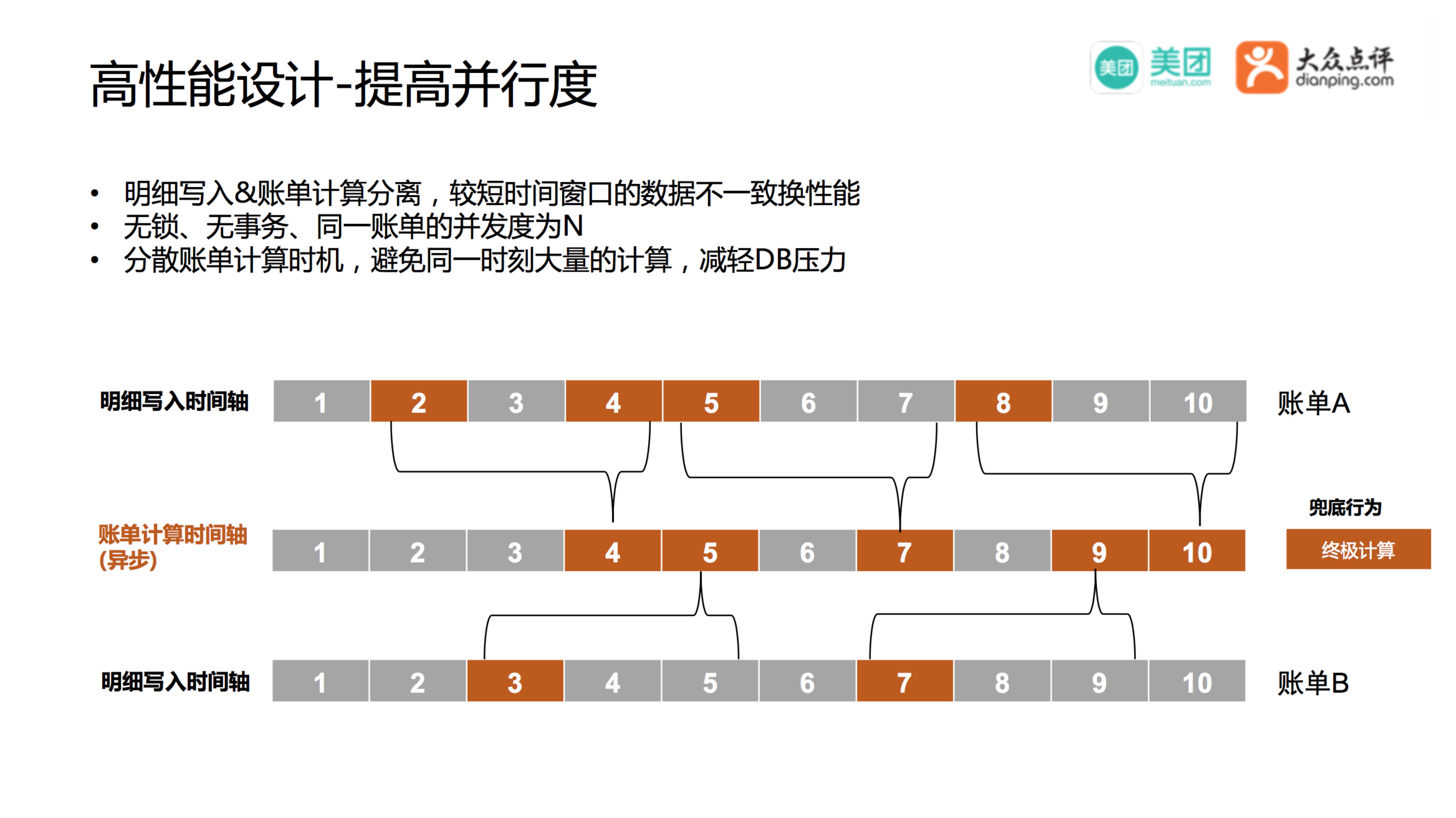
我们对商家的操作习惯进行了分析,商家更关注账单的总金额,不太关注交易明细,只要能保证账单总金额的计算相对实时,最终是正确的就好了,所以我们将账单明细的写入和账单的计算做了分离,不保证原子性,这样就省去了事务的性能开销,账单明细只管写入,不用关注账单的计算,全程不显式加锁,提高了明细的写入效率,Mafka的消息出列也变的更快。
另外一方面,我们为每个账单抽象了写入时间轴,通过写入时间推算账单的计算时间。假设我们配置账单的延迟计算窗口为3秒,账单A在第2秒和第4秒的写入都会在第4秒合并成一次计算,账单B在第3秒和第5秒的写入都会在第5秒合并成一次计算,账单没有明细写入不触发计算。这样在商家的视角账单总金额会有最多3秒钟的延迟,从体验上来看也是完全可以接受的。
每个账单的写入时机不同,每个账单的计算时机也不同,所以可以将多个账单的计算时机随机相对均匀的分散开,减轻DB的压力,每个账单在最终结账时都会有一次终极的兜底计算,防止计算异常。最终做到了无事务、无锁,单账单并行度也从1变成了N,提高了单账单的处理效率。
提高读性能
场景一
以前边所提账单的计算为例,核心语句如下:select sum(金额) from 账单明细表 where 账单ID = X,当数据规模在亿级怎么保证效率?我们除了在账单ID维度增加索引以外,还通过分表,数据备份的方式尽可能保证单表里数据量不至于太大,来提高处理效率。
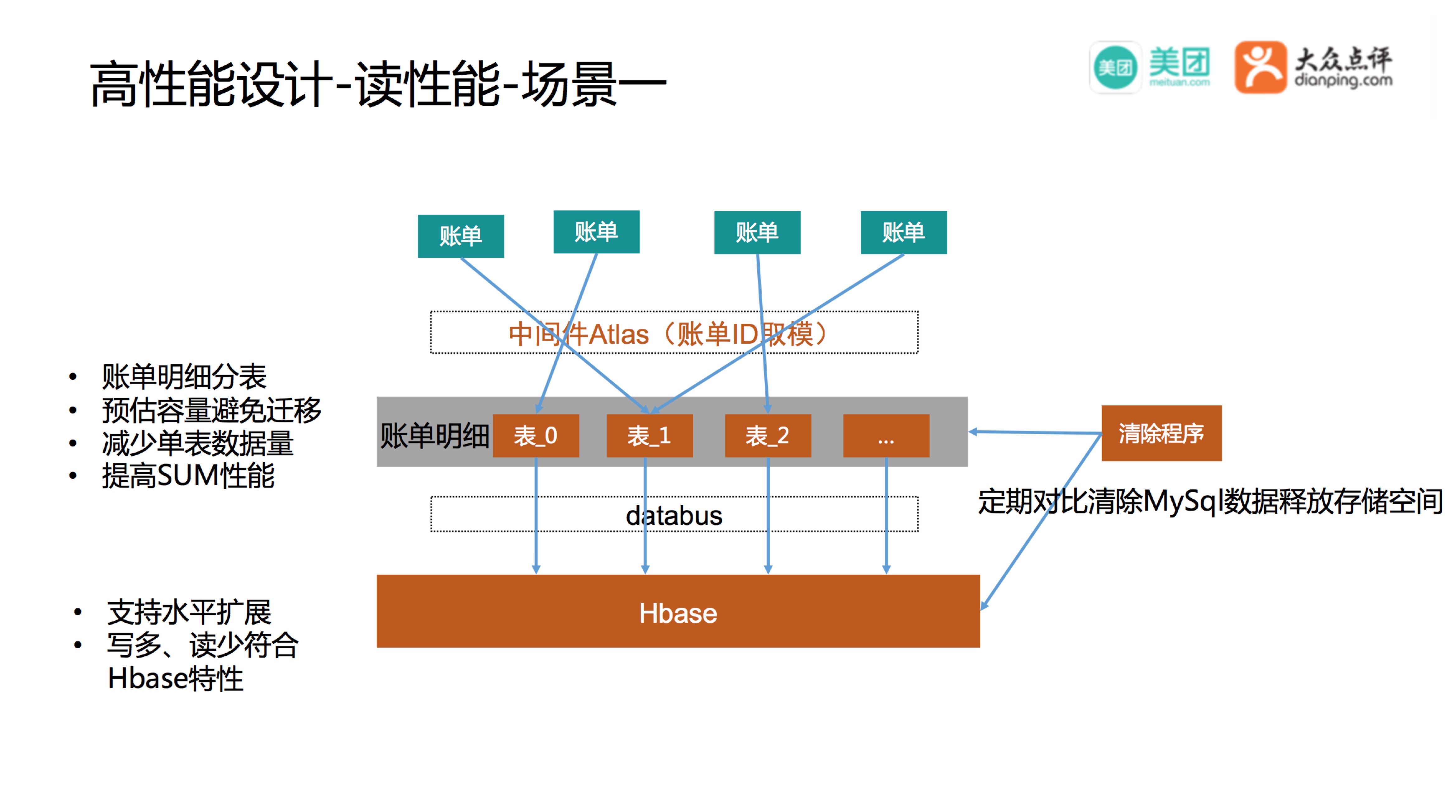
通过中间件atlas,账单明细按照账单ID取模的方式进行分表,保证同一个账单明细在一张表中,虽然会有一定的数据分布不均匀的问题,但是在很大程度上也能避免同一个表过于庞大,从而提高的SUM操作的性能。
账单明细有一个特性是不可变更,我们的业务场景是写多\读少,HBase也支持水平扩展,很适合做数据备份,所以我们通过Databus将数据同步到HBase中一份,还设计了一个程序定期的去对比MySQL和Hase的中的数据,账单结账后就不需要SUM操作了,经过一定的周期以后可以将MySQL中的明细做清除,释放MySQL的存储空间,只要一开始账单明细容量预留的足够大,通过这样的策略基本上能避免后续业务规模化后扩容产生的数据迁移问题,但是会有另外一个问题是需要定期处理数据库因为删除操作而产生的表空间空洞问题。
场景二
数据完整性校验,保证一个商家的一个账单数据是完整的,核心语句如下:select count(1) from 流水表 where 业务线=酒店 and 商家ID=1 and 流水时间 > X and 流水时间 < Y and 数据状态 = 未处理 。数据量在亿级如何保证效率?
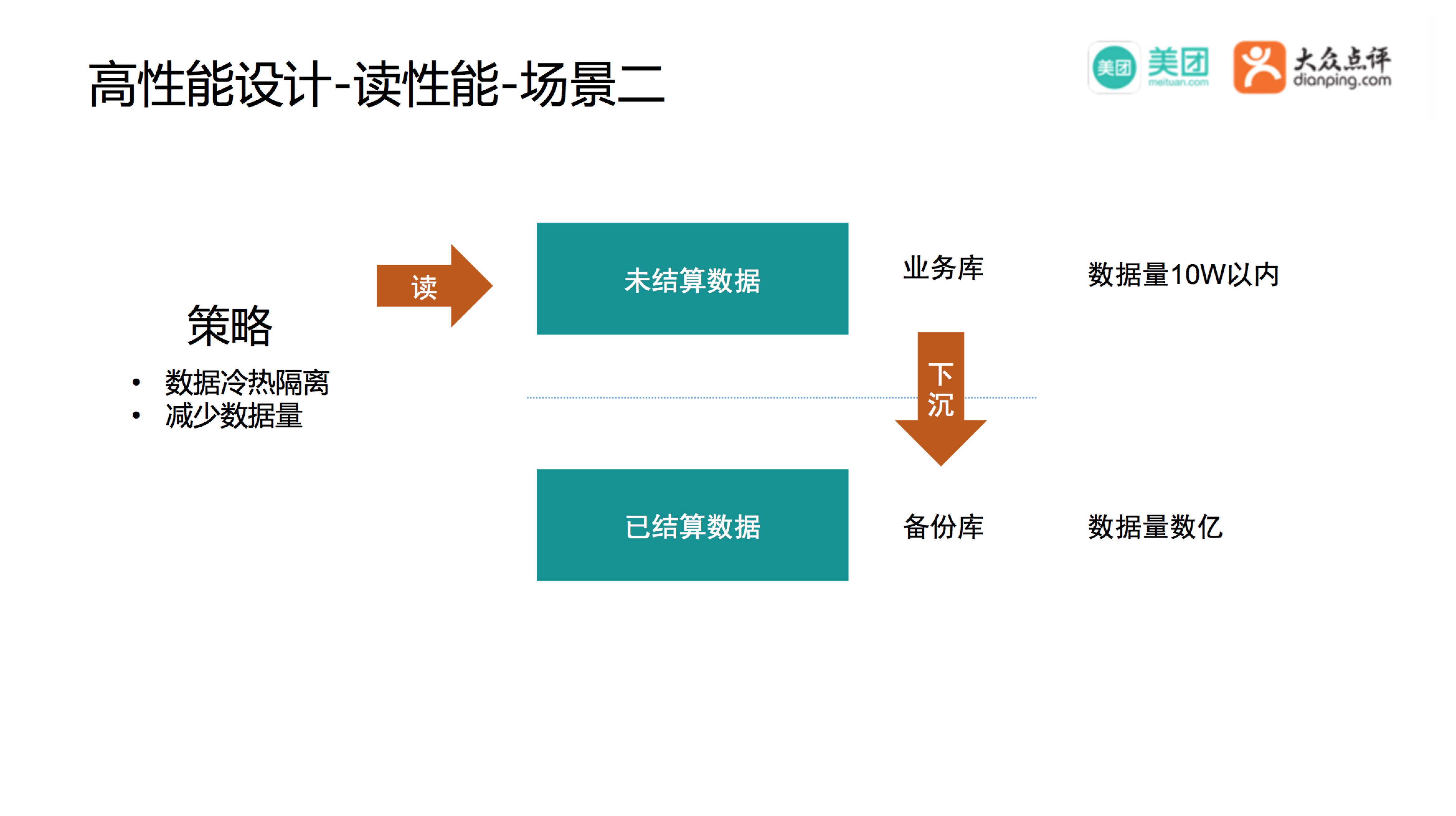
我们将交易明细做了冷热隔离,将已结算的数据备份到备库中,未处理的数据整体量级在10万条以内,主要是不到结算时机或者在途的一些数据,在配合一些索引,整体的处理效率是非常高的。
DB读写未来的规划
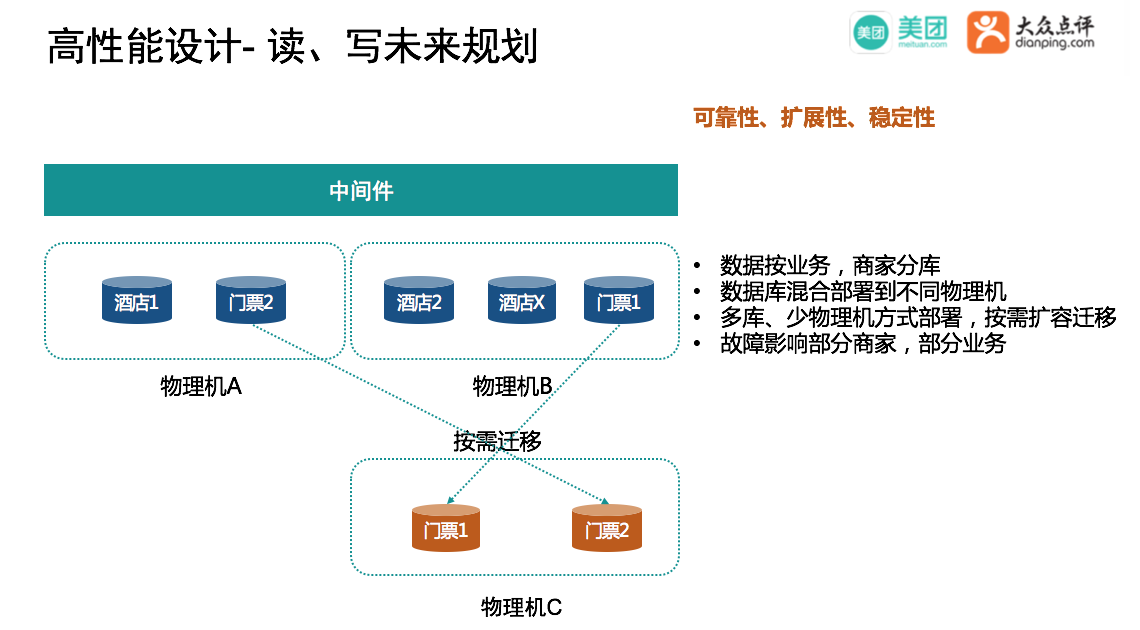
未来会根据业务和商家分库,前期采用多库,少物理机的模式部署,避免资源浪费。当物理机容量不足时按需迁移到新的物理机,整个过程只会较短时间的block写,对读无影响,迁移较为方便,目的是为了消除DB单点问题,故障只影响部分商家,部分业务。另一方面通过分库,多物理的机的形式也能提高DB层面的读、写能力。
隔离和定制
结算平台对接了17条业务线,不同业务体量不同,所需要的系统容量也不同,怎么定制化扩容?业务也会有一些特殊流程和逻辑怎么做逻辑定制?怎么做到A业务线故障不影响B业务线?
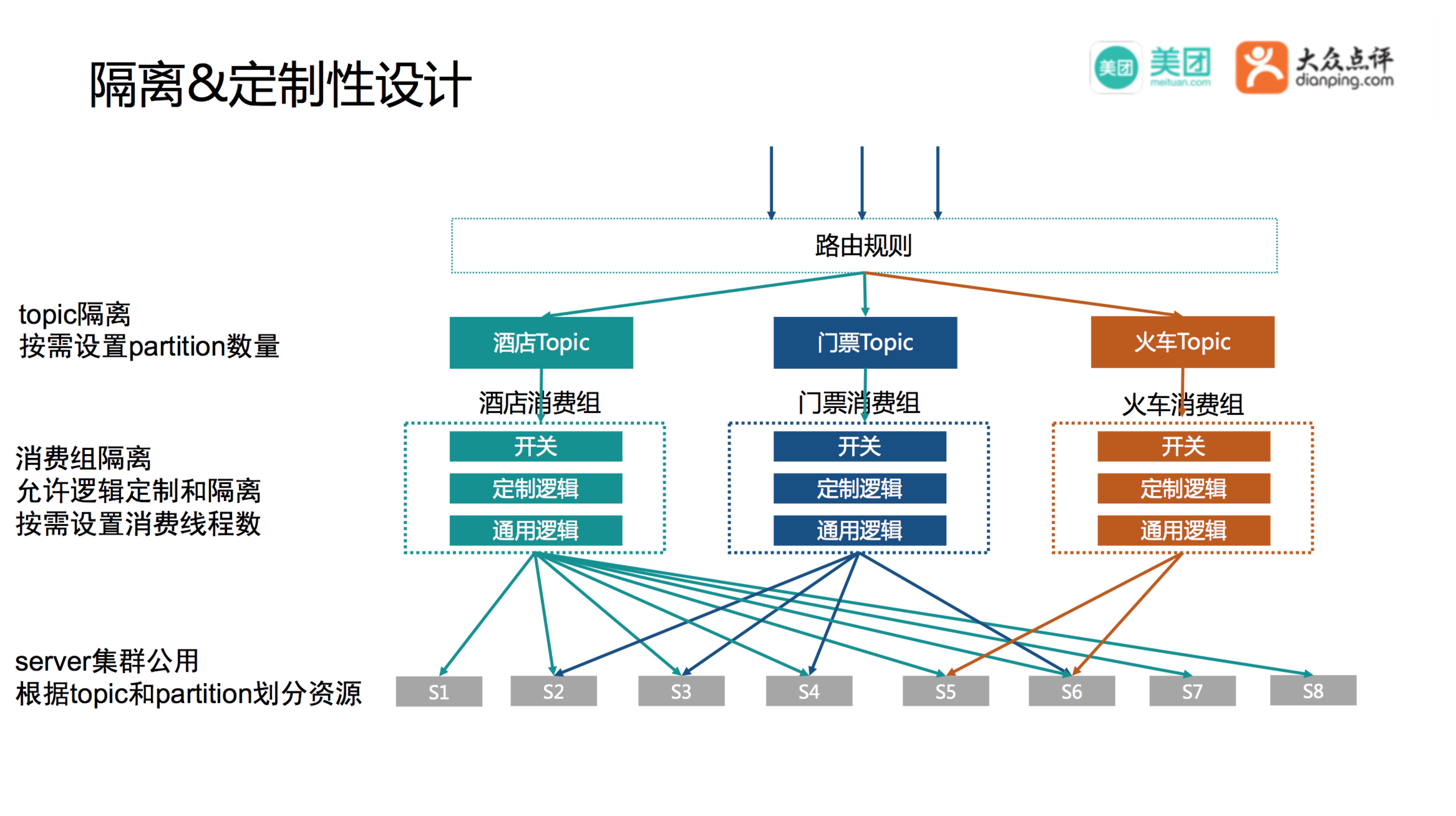
如上图,我们根据一定的路由规则,将数据灌到不同的Topic中,酒店体量比较大可以针对酒店Topic配置较多的Partition,火车票体量没有酒店大可以配置相对少的Partition,针对不同的消费组配置不同的消费线程数,从而做到给不同业务分配不同的系统容量。账单引擎由通用逻辑+定制逻辑实现,定制逻辑以消费组维度做隔离,每个消费组配置单独的开关,当业务产生异常需要暂停结算时,关掉开关,对其他业务无影响。Server集群公用,通过Mafka的机制根据Topic和Partition自动划分资源,最终做到个性化扩容,多业务隔离相互不影响。
整体扩展性设计
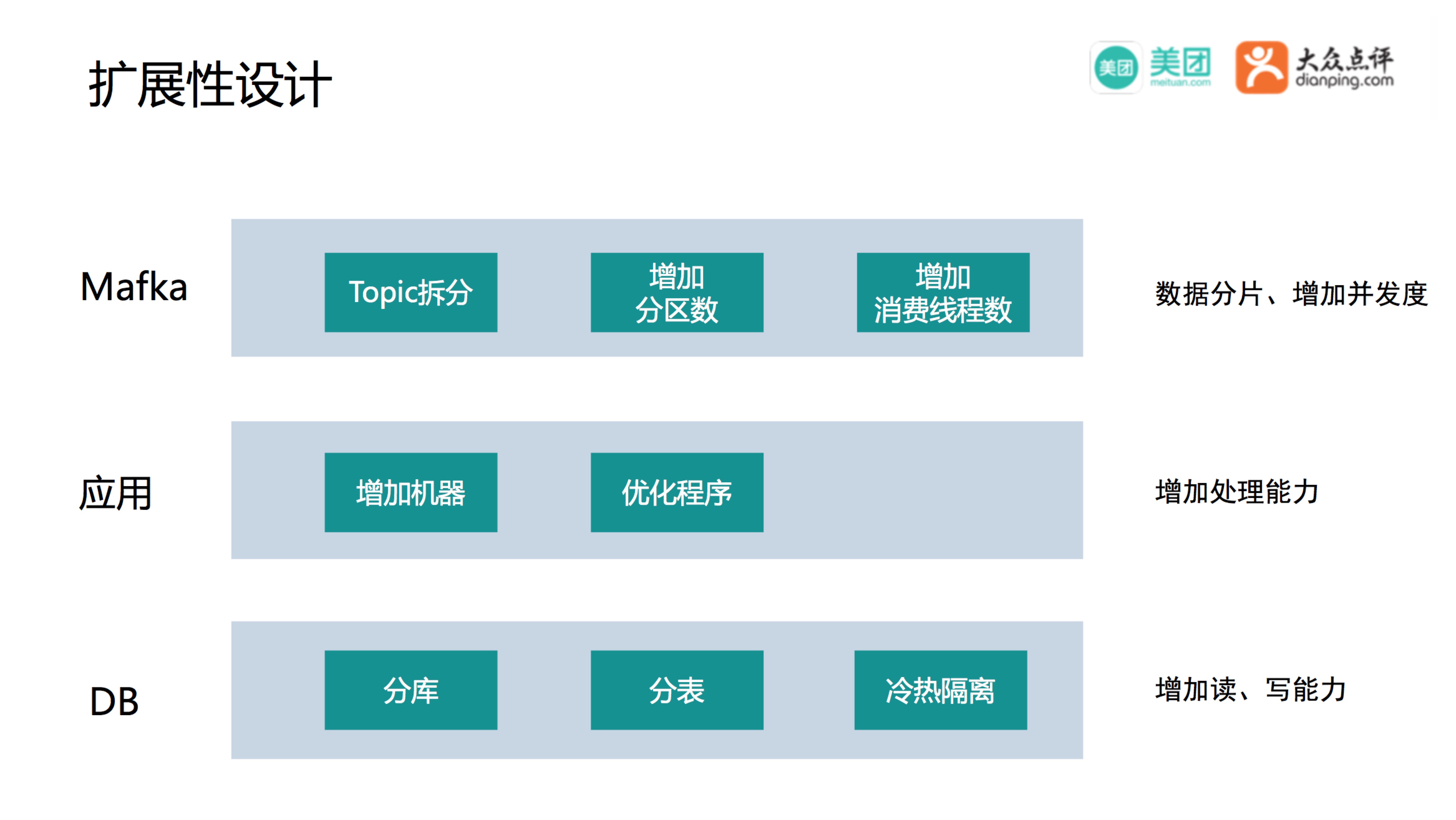
主要分三层:
- 第一层是消息中间件,可以通过拆Topic、Partition,增加消费线程数,来提高整体的并发度。
- 第二层是通过程序优化,增加机器,从而提高并行度和整体的处理能力。优化程序如前边提到的减少锁和事务,分散数据压力等手段。
- 第三层DB这块可以通过分库、分表、冷热隔离,提升整体的读写能力。
整体的扩展是需要多层进行配合的,比如Mafka的并发度特别高,Server数也特别多,但是只有一个DB,DB可能就是一个瓶颈,那就需要在DB的层面做一些扩展和优化。
最后呈现出的效果是,数据接入基本上延迟是在毫秒级别,对账单是实时对账单,产生交易后商家立刻就能在账单上看到收入明细,对商家来说体验非常好,对接了17条业务线,从不交叉影响。
作者简介
- 子鑫,2015年7月加入美团,目前是酒旅结算平台技术负责人。之前在京东和去哪儿从事订单交易相关的一些工作。
招聘信息
结算平台目前在招Java后台研发工程师,感兴趣的可以投递个人简历到邮箱:zhangzixin03#meituan.com,欢迎您的加入。